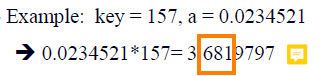2022. 12. 13. 19:11ㆍ자료구조
1. Serial Search: 인덱스 앞부터 순서대로 찾는법
*Worst-case: O(n)의 시간복잡도 소요
2. Binary Search: 정렬된 배열에서 (시작인덱스+마지막 인덱스)/2 인덱스 다음부터 내가 찾고자 하는 것을
탐색

찾고자하는 값이 더 크다면 (5+마지막 인덱스)/2 로 반복
찾고자하는 값이 더 작다면 (시작인덱스+3)/2로 반복
* worst-case: log(n)의 시간복잡도
3. Hashing: 원래의 값(key)을 해쉬함수를 이용하여 변환한 후 해당 인덱스에 저장
-> 값을 찾을 때 key값을 이용해 탐색
*collision: 서로 다른 키 값이 해쉬함수로 같은 인덱스로 배정받는 경우 충돌했다고 한다.
해결방안)
Open-Address Hashing(개방 주소법)
: 충돌이 난 경우 다음인덱스로->비어있지 않다면 그 다음 인덱스로 저장 (반복)
1) linear probing : 충돌나면 다음 위치로 가서 첫번째로 만난 빈공간에 보관하는 방법
2) Double Hashing :
1번 방법의 문제점- 원소들이 한곳에 뭉쳐있는 현상(clustering)이 발생할 수 있음 -> 삽입하는 데 오래걸림
그게 해결책- 바로다음 위치의 빈공간이 아닌 더 멀리 가서 위치해놓는 방법
키값에 의해 얼만큼 더 가서 저장할지가 정해진다.
Chained Hashing
: 해당 인덱스로 가야하는 모든 데이터들을 링크드리스트로 만들어서 저장
-> 인덱스에서는 해당 링크드리스트를 가리키도록 하는 기법
* 개방 주소법을 사용하는 Table Class 만들기
template <class RecordType>
class table
{
public: …
private: …
RecordTypedata[CAPACITY] ; //값들을 해쉬함수를 통해 저장할 배열(해쉬 테이블)
std::size_t hash(int key) const ; //해쉬값을 변환해주는 함수(해쉬 함수)
std::size_t used ;//해쉬 테이블에 저장되어있는 데이터의 수
…
}
*생성자- 해쉬 테이블의 각각의 인덱스를 NEVER_USED 상태로 초기화
(NEVER_USED: 인덱스를 한번도 사용하지 않은 상태를 나타내는 상수)
used=0으로 초기화
*insert(entry): 삽입하는 함수
1. entry에 해당하는 key가 인덱스에 존재하는지 확인
2. 존재하지 않는다면
배열의 크기가 여유있는지 확인
해쉬값에 해당하는 첫번째 빈공간을 찾고, 그 위치=인덱스 번호
used ++;
3. 인덱스 번호 값 세팅
*remove(key) : key에 해당하는 값 제거하는 함수
1. key에 해당하는 value 제거
2. 해당 인덱스 PREVIOUSLY_USED 상태로 변경
(PREVIOUSLY_USED: 배정받은 적 있는 인덱스를 표시하는 상수)
3. used--;
* PREVIOUSLY_USED와 NEVER_USED 상태를 쓰는 이유?
삽입,삭제 함수를 사용할 때 NEVER_USED 상태를 만나면
그 다음 인덱스를 탐색안해도 되서 성능 향상되기 때문
*해쉬값 변환하는 함수 알고리즘
1. Division Hash Functions
: key % table_size
2. Mid_Square Hash Functiones
: 좋은 테이블 사이즈는 4k+3 형태의 소수
key*key -> 이진수로 표현 ->
테이블 사이즈를 2의 제곱승으로 표현했을 때 지수값만큼 이진수로 표현한 값의 가운데 값들을 취함
-> 취한 이진수를 10진수로 변환 ->그걸 해쉬값으로 사용

3. Multiplicative Hash Functions
: key* a (0<a<1)의 값의 소수값의 적당한 숫자를 취함