2024. 6. 11. 03:14ㆍ데이터베이스
table index
: 테이블 속성을 사용하여 효율적으로 액세스 할 수 있도록 구성.
각 쿼리를 실행하는 데 사용할 최적의 인덱스를 찾는 것이 DBMS의 작업이다.
B+ Tree
: 데이터가 정렬된 상태를 유지하고
검색, 순차적 액세스, 삽입 및 삭제를 항상 O(log n) 시간으로 가능
-> 대용량 데이터 블록을 읽고 쓰는 시스템에 최적화
-> 모든 리프 노드가 트리의 동일한 깊이에 있다
-> 루트 이외의 모든 노드는 최소한 절반은 차있다.
-> k개의 키를 가진 모든 내부 노드는 k+1개의 null이 아닌 자식을 가진다
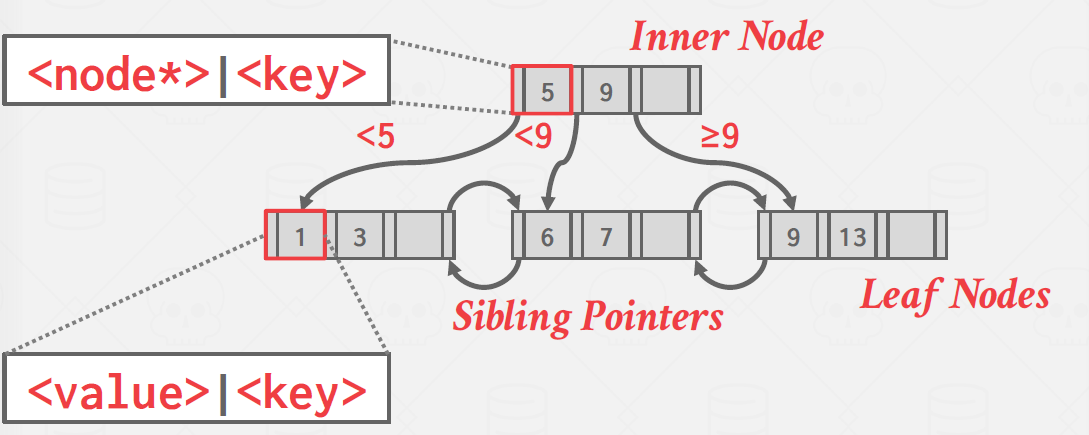
노드
- 모든 B+Tree 노드는 키/값 쌍의 배열로 구성
- 키는 인덱스의 기반이 되는 속성에서 파생
- 값은 노드가 내부 노드로 분류되는지 아니면 리프 노드로 분류되는지에 따라 달라진다.
- 배열은 (일반적으로) 정렬된 키 순서로 유지

Prev는 첫번째 키값보다 작은 키값을 가지는 노드를 가리키는 포인터
Next는 마지막 키값보다 큰 키값을 가지는 노드를 가리키는 포인터
Leaf node Value
1. Record Ids
: 튜플의 위치를 가리키는 포인터를 leaf node에 저장
2. Tuple data
: 튜플의 실제 내용을 저장
-> 보조 인덱스는 Record ID를 값으로 저장
보조 인덱스로 기본키가 들어있어
기본키로 테이블에서 원하는 정보를 찾는다.
-> 인덱스별로 실제 값을 다 저장하면 중복되는 데이터가 생겨서 비효율적이다.
-> 기본키로 검색이 자주 일어나면 이 방법이 더 빠르다.
B-Tree: 모든 노드에 key값과 value값이 저장B+ tree: leaf node에는 value값만 저장.
B+ Tree 삽입 알고리즘
1. 값이 들어갈 leaf node를 찾는다2. 정렬된 상태로 삽입된다3. 자리가 충분하다면 끝.3-1 자리가 부족하다면 두 개의 노드로 분할-> 내부 노드를 분할하려면 항목을 균등하게 재분배하되 중간 키를 위로 밀어 올린다
B+ Tree 삭제 알고리즘
1. 삭제하고자 하는 값을 가진 leaf 노드 찾기
2. 값 삭제
3. 삭제하고 노드에 값이 반이상 차있다면 끝.
3-1 그렇지 않다면 형제 노드로부터 값을 가져와서 재분배
-> 형제들도 값이 부족하다면 형제와 merge

중복 키
중복되는 키 처리 방법
1. Record ID
: 튜플의 고유한 ID를 B+ tree의 키와 함께 저장.
키가 중복되더라도 튜플 ID는 고유하기 때문에
(키, 튜플 ID)의 조합은 고유하다.
Clustered index
- primary key를 인덱스로 활용
- primary key를 기준으로 테이블을 정렬
- 어떤 DBMS들은 항상 이 방식을 사용
-> primary key가 없어도 자동으로 hidden primary key를 만들어 저장 - range scan 처리 성능이 좋다.
-> 디스크 상의 데이터가 primary key를 기준으로 정렬됐기 때문에
순서대로 저장되어 있으므로 쭉 읽으면 된다
Non-clustered index
- 인덱스를 구성하는 칼럼을 기준으로 정렬
- 키의 순서와 디스크에 저장된 데이터의 순서가 일치하지 않다
-> 뒤죽박죽 있으니깐 여러 번 읽어야 한다(random access) - Index scan page sorting방법으로 random access를 줄일 수 있다
-> 1. 찾고자 하는 데이터가 속한 page ID들을 구한다
2. 다 찾으면 page ID를 기준으로 정렬시킨다
3. 정렬된 순서로 페이지에 접근해서 찾고자 하는 데이터를 가져온다
B+ Tree는 저장된 장치가 느릴수록 효과적이다.
'데이터베이스' 카테고리의 다른 글
| Hash Tables (0) | 2024.05.15 |
|---|---|
| 7. Storage (1) (0) | 2024.05.01 |
| 6. Normalization (0) | 2024.04.16 |
| 5. E-R model (0) | 2024.04.08 |
| 4. Modern SQL (1) | 2024.04.02 |